


Looker Studio(旧Googleデータポータル)で複数のデータソースを結合・統合したいけれど、設定方法がわからない、結合演算子の違いがわからない、エラーが出て困っている——そんな悩みを抱えていませんか?
本記事では、Looker Studioのデータ統合(ブレンド)機能を使ったデータ結合の方法を、基礎知識から実践的なテクニックまでステップバイステップで解説します。
この記事でわかること:
- データ統合(ブレンド)の仕組みと基本概念
- 5種類の結合演算子(LEFT JOIN・INNER JOINなど)の違いと使い分け
- Looker Studio上でのデータ結合の具体的な操作手順
- GA4×Google広告など実務で使える統合パターン
- 結合時によくあるエラーの原因と対処法
なお、Looker Studioの「データ統合」は、SQLでいう「JOIN」に相当する機能で、公式ドキュメントでは「ブレンド」とも呼ばれています(参考:Google公式ドキュメント – Looker Studioでの統合の仕組み)。本記事では「データ統合」「データ結合」「ブレンド」を同義として扱います。
データ統合(ブレンド)とは、複数のデータソースを共通のキーを使って1つのデータセットにまとめる機能です。Looker Studioでは、SQLのJOIN文に相当する操作を、コードを書かずにGUI上で行うことができます。
例えば、「日付」をキーにして、GA4のアクセスデータとGoogle広告の広告費用データを結合することで、広告費用対効果(ROAS)の分析レポートを1つのグラフ上で作成できるようになります。
データ統合を使うメリット
Looker Studioのデータ統合機能を使用することで、以下のようなメリットが得られます。
- 異なるデータソースの情報を統合し、包括的な分析が可能になる
GA4のアクセスデータ、Google広告のコストデータ、スプレッドシートの売上データなどを1つのレポートで横断的に分析できます。 - データの二重管理を防ぎ、メンテナンス性が向上する
元のデータソースを更新するだけで、統合されたレポートにも自動的に反映されます。 - リアルタイムでデータを更新しながら結合が可能になる
BigQueryやGA4などリアルタイム性のあるデータソースを使えば、常に最新のデータで分析できます。
特に重要なのは、データ統合によって単一のデータソースでは実現できない新しい切り口での分析が可能になる点です。
例えば、GA4のアクセスデータとGoogle広告データを統合すれば、広告効果とユーザー行動の関係性を深く理解できます。また、GA4とSearch Consoleのデータを組み合わせることで、どの検索キーワードからの流入がコンバージョン率が高いかを分析することも可能です(参考:Google公式ブログ – Looker StudioでSearch Consoleのデータと内部データを統合する)。
様々なレポートを取り扱っております。用途やシーンに合わせて、最適なレポートを使っていただくことで、日々のレポート作成やデータ分析のお役に立ちます!
レポート一覧はこちら
データ結合の基本的な仕組み
データ結合は、以下の3つの要素で構成されています。
- 結合キー:データを紐付けるための共通項目
- 結合元テーブル:主となるデータソース
- 結合先テーブル:追加で結合するデータソース
これらの要素を正しく設定することで、意図した通りのデータ統合が実現できます。
【表:データ結合の基本構成要素】
| 要素 | 説明 | 例 |
|---|---|---|
| 結合キー | データを紐付ける共通項目 | 顧客ID、日付、商品コードなど |
| 結合元テーブル | 主となるデータソース | Google アナリティクスのデータ |
| 結合先テーブル | 追加で結合するデータソース | スプレッドシートの顧客データ |
上記は例として挙げておりますが、結合するデータソースやどのような分析をしたいかによって、どの情報をキーにするかなどは変動がありますので、本記事で詳しく解説していきます。
データを結合する以外に独自で計算フィールドを作成して分析する手法もありますので、参考にしてください。

Tips: データ統合で作成された「統合」リソースは、作成元のレポートに埋め込まれるため、他のレポートで再利用することはできません。ただし、レポートをコピーすると統合もコピーされます(参考:Google公式ドキュメント)。
Tips: データを結合する以外に、独自で計算フィールドを作成して分析する手法もあります。詳しくは下記の関連記事を参考にしてください。
→ Looker Studio CASE関数の使い方完全ガイド|初心者でも5分でマスター
Looker Studioでデータ結合を実行する手順について、具体的に解説します。画面の操作から設定項目まで、順を追って説明していきます。
統合画面へのアクセス方法
データ結合の作業は、「統合を管理」画面から開始します。手順は以下の通りです。
- Looker Studioのレポート編集画面を開きます
- 画面上部のメニューから「リソース」をクリックします
- ドロップダウンメニューから「統合を管理」を選択します
- 「統合を追加」ボタンをクリックして新規作成を開始します
この操作により、データ結合の設定画面が表示されます。ここから実際のデータソースの選択と結合設定を行っていきます。
操作自体は難しいわけではないですが、データの構造を理解した上で結合しないと、分析したいデータを取得することができません。
データソースの選択と設定
データソースの選択は、結合の成否を左右する重要なステップです。以下の点に注意して設定を行います。
- 結合元データソースの選択
- 主となるデータを含むソースを選択します
- 例:Google アナリティクスのデータなど
- 結合先データソースの追加
- 追加で統合したいデータソースを選択します
- 複数のデータソースを順次追加することも可能です
- 使用するフィールドの選択
- 必要なディメンションと指標を選択します
- 不要なフィールドは非表示にして管理を簡潔にします
【表:データソース選択時のチェックポイント】
| 確認項目 | 内容 | 注意点 |
|---|---|---|
| データ形式 | CSV、スプレッドシート、BigQueryなど | 形式に応じた前処理が必要な場合があります |
| 更新頻度 | リアルタイム、日次、週次など | 結合後のデータ更新タイミングを考慮します |
| データ量 | レコード数、カラム数 | 処理負荷とパフォーマンスに影響します |
データソースは分析したいデータが含まれており且つ、キー(一意)なデータと連携させることができるデータが結合したいデータ2つともに含まれている必要があります。
結合キーの設定方法
結合キーの正しい設定は、データ結合の精度と信頼性を確保する上で極めて重要です。以下の手順で設定を行います。
結合キーを誤ると分析ができない、もしくはエラーになることが多々あります。
- 結合キーの特定
- 両方のデータソースに共通する一意の識別子を選択します
- 例:顧客ID、取引コード、日付など
- データ型の確認
- 結合キーのデータ型が両方のソースで一致していることを確認します
- 文字列、数値、日付などの型の統一が必要です
- キーの組み合わせ設定
- 複数のフィールドを組み合わせて結合キーとすることも可能です
- 例:日付と商品コードの組み合わせなど
よくあるエラーと解決方法
データ結合時に発生しやすいエラーとその対処方法について説明します。
もっとエラーとして多いのがデータの不一致になります。結合する2つのデータにキーになるものがなく、正しくデータが取得できないことによるエラーが多いです。その場合はの対策も記載しておりますので参考にしてください。
- データ型の不一致
- 症状:結合キーのデータ型が異なるためエラーが発生
- 解決策:データ型を揃える前処理を実施
- 重複データの存在
- 症状:予期せぬデータの重複が発生
- 解決策:重複を除去するフィルタの適用
- パフォーマンスの低下
- 症状:データ量が多く処理が遅くなる
- 解決策:不要なフィールドの削除や集計の事前実施
【表:主なエラーと対処方法】
| エラー種類 | 主な原因 | 対処方法 |
|---|---|---|
| 型の不一致 | 文字列と数値の混在 | データ型の変換処理を追加 |
| 結合キー未設定 | キーの選択漏れ | 必須フィールドの確認 |
| メモリ不足 | データ量過多 | 不要フィールドの削除 |
これらの設定と注意点を理解することで、安定したデータ結合の実装が可能になります。次のセクションでは、具体的な結合の種類と使い分けについて解説します。
上記以外でのLooker studioのエラーの対応方法は下記のページを参考にしてください。

Looker Studioでは、データ分析の目的に応じて異なる種類の結合方法を選択できます。それぞれの結合タイプには特徴があり、適切な使い分けが分析の質と分析できる内容が左右します。
このセクションでは、各結合タイプの特徴と具体的な活用シーンについて解説します。
左外部結合(LEFT JOIN)の活用シーン
左外部結合は、Looker Studioで最も一般的に使用される結合方法です。この結合方法では、左側(結合元)のテーブルのすべてのデータを保持しながら、右側(結合先)のテーブルから一致するデータを追加します。
もっとも使用頻度が高い結合方法になります。
左外部結合が特に効果的なのは以下のような場合です。
- ベースとなるデータを保持しながら補足情報を追加したい場合
例:アクセスログデータ(左側)に、ユーザー属性データ(右側)を追加する - 欠損値の分析や補完が必要な場合
例:販売データ(左側)に商品マスタ(右側)を結合し、商品情報が登録されていない商品を特定する
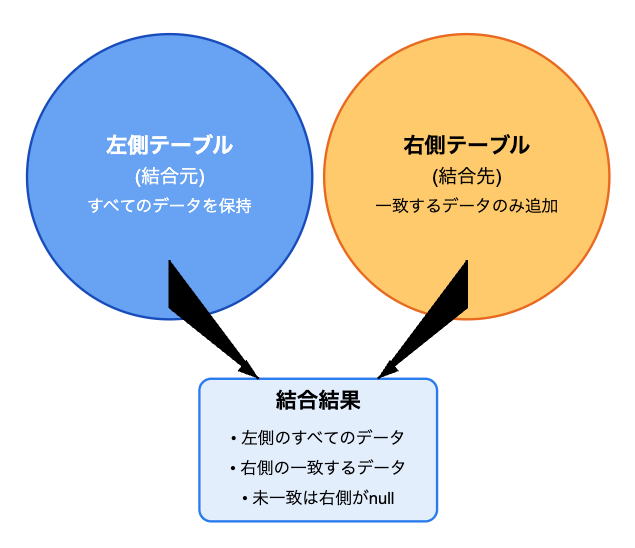
【表:左外部結合の特徴】
| 項目 | 説明 |
|---|---|
| データの保持 | 左側のデータはすべて保持 |
| 結合条件 | 一致しないデータも表示(右側はnull) |
| 主な用途 | 基準となるデータへの情報追加 |
| 注意点 | 右側テーブルの未一致データは失われる |
左側のデータは全て保持された状態で結合するため、左側のデータが基準になります。
どちらのデータが基準になるかを理解しておくことで、結合の際に迷わず設定することができるかと思います。
内部結合(INNER JOIN)の実践的な使い方
内部結合は、両方のテーブルで結合キーが一致するデータのみを抽出する方法です。データの完全性が重要な場合や、確実に対応関係のあるデータのみを分析したい場合に適しています。
つまり、両方テーブルで同じ情報が必要になります。例えば、ユーザーIDは両方のテーブルであり、誰が買ったかの情報と誰がどの決済で買ったなどの情報になります。
両方でユーザーIDがあれば、結合して合わせたデータを分析することができます。ユーザーID:Aさんが化粧品をカード決済で購入したという分析ができます。
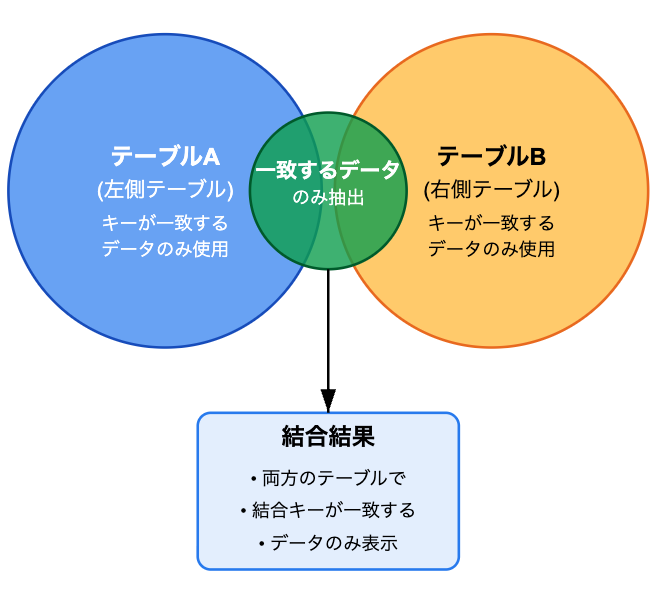
内部結合の効果的な活用シーンには以下があります。
- 確実な対応関係を持つデータの分析
例:受注データと入金データの突合せによる入金状況の確認 - クリーンなデータセットの作成
例:有効な顧客IDを持つトランザクションデータのみを抽出
【表:内部結合の活用例】
| ユースケース | 結合元データ | 結合先データ | 分析目的 |
|---|---|---|---|
| 売上分析 | 販売記録 | 商品マスタ | 商品カテゴリ別の売上集計 |
| 顧客分析 | 購買履歴 | 顧客属性 | セグメント別の購買動向把握 |
| 広告効果測定 | クリックログ | コンバージョンデータ | 広告経路別の成約率算出 |
完全外部結合(FULL OUTER JOIN)の実践的な使い方
完全外部結合は、両方のテーブルのすべてのデータを保持する結合方法です。データの欠損状況を把握したい場合や、包括的な分析が必要な場合に使用します。完全外部結合は使用頻度としてはあまり多くはありません。
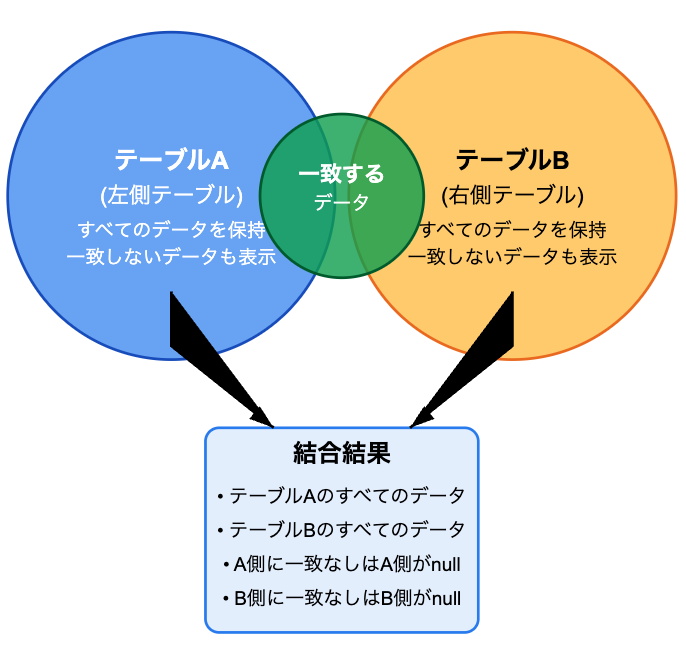
完全外部結合が有効なケース
- データの整合性チェック
例:異なるシステム間のデータ突合せによる不整合の検出 - 全体像の把握
例:すべての商品と全期間の在庫状況を網羅的に確認
【表:完全外部結合の注意点】
| 確認項目 | 内容 | 対策 |
|---|---|---|
| データ量 | 結合後のレコード数が増加 | 必要なフィールドのみを選択 |
| 処理速度 | 大量データの場合に低下 | 事前の集計やフィルタリング |
| 重複確認 | 意図しない重複の可能性 | 結合後のデータ検証を実施 |
クロス結合(CROSS JOIN)の特殊な活用法
クロス結合は、両方のテーブルのすべての組み合わせを生成する特殊な結合方法です。一般的な分析では使用頻度は低いものの、特定のケースでは非常に有用です。
クロス結合の活用シーン
- マスターデータの組み合わせ作成 例:商品と店舗の全組み合わせによる在庫管理表の作成
- 分析用の基準データの生成 例:日付と時間帯の組み合わせによる時系列分析の基準データ作成
【表:クロス結合使用時の注意点】
| 注意点 | 説明 | 対策方法 |
|---|---|---|
| データ量 | 組み合わせによる爆発的な増加 | 事前のフィルタリング |
| パフォーマンス | 処理負荷が高い | 必要最小限の範囲で使用 |
| 用途の適切性 | 特定用途以外では非推奨 | 他の結合方法の検討 |
これらの結合方法を適切に使い分けることで、より効果的なデータ分析が可能になります。次のセクションでは、これらの結合方法を活用した具体的な実践例を紹介します。
様々なレポートを取り扱っております。用途やシーンに合わせて、最適なレポートを使っていただくことで、日々のレポート作成やデータ分析のお役に立ちます!
レポート一覧はこちら
データ結合の基本を理解したところで、実際のビジネスシーンでの活用例を詳しく見ていきましょう。ここでは、よくあるデータ分析のニーズに対して、Looker Studioのデータ結合機能をどのように活用できるかを具体的に解説します。
Googleアナリティクスと広告データの統合
マーケティング効果の総合的な分析において、Googleアナリティクスと広告データの統合は非常に重要です。この統合により、広告投資の効果をより深く理解することができます。
一部のデータはGoogleアナリティクスからも取得することはできますが、より深いデータはGoogle広告のデータソースから取得してくる必要があります。
統合の具体的な手順は以下の通りです。
まず、Googleアナリティクスのデータを結合元として設定します。このデータには、ユーザーの行動データ(セッション数、ページビュー、滞在時間など)が含まれています。
次に、Google広告やMeta広告などの広告データを結合先として追加します。結合キーには「日付」と「キャンペーンID」を使用することで、日次での広告効果分析が可能になります。
この統合により、以下のような高度な分析が可能になります。
- キャンペーン別のコンバージョン率と費用対効果の把握
- 広告チャネル間のクロス集計による相乗効果の分析
- ユーザー行動と広告接触の時系列分析
カスタムフィールドの作成と活用
データ結合後、さらに高度な分析を行うためにカスタムフィールドを作成することができます。カスタムフィールドは、結合したデータを基に新しい指標を計算する機能です。
例えば、以下のようなカスタムフィールドを作成することで、分析の幅が広がります。
- 売上高と広告費用から算出するROAS(広告費用対効果)
- 来訪者数とコンバージョン数から計算する転換率
- 前年同月比や前月比などの時系列での変化率
下記のページで計算フィールドの使い方を解説しておりますので参考にしてください。
データ結合を実施する際には、さまざまな課題や問題が発生する可能性があります。このセクションでは、Looker Studioでよく遭遇するトラブルとその具体的な解決方法について説明します。適切な対処方法を理解することで、スムーズなデータ分析の実現が可能になります。
パフォーマンス問題の解決策
データ結合時のパフォーマンス低下は、分析作業の大きな障害となります。主な原因は、大量のデータ処理や非効率な結合処理にあります。以下に、具体的な対策方法を説明します。
データ量が多い場合は、まず分析の目的に必要なデータ範囲を見極めることが重要です。例えば、過去3年分のデータすべてを結合する代わりに、直近1年分に絞ることでパフォーマンスが大幅に改善することがあります。また、データの前処理として集計や要約を行うことで、処理すべきレコード数を削減できます。特にスプレッドシートやエクセルなどをデータソースとして使用している場合には、かなり有効な手法になります。
データ型の不一致への対処法
データ型の不一致は、結合処理の失敗や予期せぬ結果の主な原因となります。
最も一般的な例として、日付データの形式の違いがあります。例えば、一方のデータソースでは「2024-04-06」という形式で、もう一方では「2024/04/06」という形式で日付が保存されているケースです。このような場合、以下の手順で対処します。
まず、データ型の確認を行います。各データソースのフィールドの型を確認し、不一致がある場合は適切な型に変換します。日付データの場合、標準的なISO形式(YYYY-MM-DD)に統一することをお勧めします。
重複データの処理方法
データ結合後に発生する重複レコードは、分析結果の精度に重大な影響を及ぼす可能性があります。この問題に対する効果的な対処方法を説明します。わざと重複データを分析する場合はよいですが、それ以外の場合は、削除してデータを削減しておく方が良いです。
重複データの処理では、まず重複の発生原因を特定することが重要です。多くの場合、以下のような原因が考えられます。
結合キーの設定が不適切である可能性があります。例えば、「日付」のみを結合キーとした場合、同じ日付の複数のレコードが意図せず結合される可能性があります。この場合、より詳細な識別子(取引ID、顧客IDなど)を結合キーに追加することで解決できます。
Looker Studioのテンプレや分析などにお困りの方は、お問い合わせください。
その他マーケティングに関するご相談もお受けしておりますので、お気軽にご相談ください。

データ分析の高度化に伴い、より複雑なデータ結合のニーズが増えています。このセクションでは、Looker Studioを最大限に活用するための高度なテクニックを解説します。これらの手法を習得することで、より柔軟で効率的なデータ分析が可能になります。
複数テーブルの段階的結合
大規模なデータ分析では、3つ以上のテーブルを結合する必要が生じることがあります。
結合の順序や方法を適切に設計することが重要です。例えば、ECサイトの分析において、注文データ、顧客データ、商品データを結合する場合を考えてみましょう。
まず、主となる注文データに顧客データを結合します。この際、顧客IDを結合キーとして使用し、顧客の属性情報を付加します。次に、この結果に商品データを結合します。商品コードを結合キーとして使用し、商品の詳細情報を追加します。
このような段階的な結合を行う際は、以下の点に注意が必要です。
- データの結合順序による影響を考慮すること
- 中間結果のデータ量を把握すること
- 各段階での結合キーの整合性を確認すること
- パフォーマンスへの影響を監視すること
【表:段階的結合の設計例】
| 段階 | 結合元 | 結合先 | 結合キー | 注意点 |
|---|---|---|---|---|
| 第1段階 | 注文データ | 顧客データ | 顧客ID | 顧客の重複確認 |
| 第2段階 | 第1段階結果 | 商品データ | 商品コード | 商品マスタの最新性 |
| 第3段階 | 第2段階結果 | 在庫データ | 商品コード、店舗 | データ量の増加に注意 |
計算フィールドの効果的な利用
計算フィールドを活用することで、データ結合後のより高度な分析が可能になります。例えば、売上データと在庫データを結合した後、在庫回転率を計算するケースを考えてみましょう。
以下のような計算フィールドを設定することで、より深い分析が可能になります。
- 期間売上高 = SUM(数量 × 単価)
- 平均在庫金額 = AVERAGE(期首在庫金額 + 期末在庫金額)
- 在庫回転率 = 期間売上高 ÷ 平均在庫金額
これらの計算フィールドを使用する際は、以下の点に注意が必要です。
- 計算ロジックの明確な定義
- データ型の適切な設定
- NULL値の処理方法の決定
- 集計レベルの統一
カスタムクエリの活用
より複雑なデータ加工や結合が必要な場合、カスタムSQLクエリを活用することで柔軟な対応が可能になります。特にBigQueryをデータソースとして使用している場合、この手法が効果的です。BigQueryではカスタムSQLは使用できないです。
カスタムクエリの活用例として、以下のようなケースが考えられます。
- 複雑な条件での結合処理
- Window関数を使用した時系列分析
- 複数の集計レベルの統合
- データの正規化処理
【表:カスタムクエリ活用のベストプラクティス】
| 項目 | 推奨事項 | 理由 |
|---|---|---|
| クエリの最適化 | 実行計画の確認 | パフォーマンス向上 |
| テスト実施 | 小規模データでの検証 | 動作確認の効率化 |
| ドキュメント化 | クエリの目的と構造の記録 | 保守性の向上 |
| モニタリング | 実行時間と結果の監視 | 安定性の確保 |
これらの高度なテクニックを適切に組み合わせることで、より効果的なデータ分析が可能になります。次のセクションでは、これらの知識を総合的に活用するためのベストプラクティスについて解説します。
これまでLooker Studioにおけるデータ結合の基礎から応用まで、様々な側面について解説してきました。このセクションでは、実務で活用できる具体的なベストプラクティスと、効果的なデータ結合を実現するための重要なポイントをまとめます。
運用・保守の注意点
データ結合を含むレポートの安定的な運用と効果的な保守のために、以下の点に特に注意を払う必要があります。
まず、データソースの監視と管理が重要です。各データソースの更新状況や品質を定期的に確認し、問題が発生した場合に迅速に対応できる体制を整えます。特に、外部データソースを使用している場合は、データ提供元との連携体制を確立しておくことが重要です。
誰がデータを更新させて、Looker Studioのレポートを調整するなどの役割が必要です。データが正しくてもLooker studio側で予期してないデータが入るとエラーになります。
また、定期的な見直しと最適化も重要です。利用状況や要件の変化に応じて、結合設定やパフォーマンスチューニングを適宜見直します。特に、データ量が増加傾向にある場合は、早めの対応が必要です。
【表:運用・保守のチェックポイント】
| 確認項目 | 実施頻度 | 重要度 | 具体的なアクション |
|---|---|---|---|
| データ品質 | 毎日 | 高 | 更新状況の確認、異常値の検出 |
| パフォーマンス | 週次 | 中 | 処理時間の監視、負荷状況の確認 |
| ドキュメント | 月次 | 中 | 設定内容の更新、変更履歴の記録 |
| ユーザーフィードバック | 随時 | 高 | 課題の収集、改善提案の検討 |
これらのベストプラクティスを適切に実践することで、Looker Studioのデータ結合機能を最大限に活用し、効果的なデータ分析基盤を構築することができます。次のセクションでは、実務でよく発生する質問とその回答について解説します。
Looker Studioのデータ結合について、実務でよく発生する疑問とその解決方法を解説します。これらの質問と回答は、実際のプロジェクト経験から得られた知見に基づいています。
データ結合の制限事項について
- Looker Studioでのデータ結合には、どのような制限がありますか?
- データ結合を行う際には、いくつかの重要な制限事項があります。まず、結合できるデータソースの数には制限があり、一度に結合できるのは最大5つのデータソースまでです。また、結合後のデータ量にも制限があり、処理できるレコード数には上限があります。
特に注意が必要なのは、異なるタイプのデータソース間での結合です。例えば、Google アナリティクスのデータとBigQueryのデータを結合する場合、データの更新タイミングや形式の違いによって予期せぬ問題が発生する可能性があります。
これらの制限に対処するためには、以下のような方策が有効です。まず、データの事前集計や必要なフィールドの選択を行い、結合するデータ量を適切な範囲に収めます。また、複雑な結合処理が必要な場合は、BigQueryなどのデータウェアハウス側で前処理を行うことで、Looker Studio側の負荷を軽減できます。
推奨される使用方法について
- データ結合を効果的に活用するための推奨事例を教えてください。
- データ結合の効果的な活用には、明確な目的と適切な計画が不可欠です。最も推奨される使用方法は、分析の目的に応じて段階的にデータを統合していく方法です。
例えば、ECサイトの分析を行う場合、以下のような段階的なアプローチが効果的です。最初に、基本的な販売データとユーザーデータを結合して顧客行動の基本的な分析を行います。その後、必要に応じて商品マスタや在庫データを追加し、より詳細な分析を行います。
また、定期的なレポーティングでは、データ更新のタイミングを考慮した結合設計が重要です。例えば、日次で更新される販売データと月次で更新される在庫データを結合する場合、更新タイミングの違いを考慮した適切なキャッシュ設定が必要です。
トラブル対応の基本について
- データ結合で問題が発生した場合、どのように対処すべきですか?
- データ結合時のトラブルに対しては、体系的なアプローチで対処することが重要です。まず、問題の切り分けを行い、どの段階で問題が発生しているかを特定します。
一般的なトラブルとその対処方法は以下の通りです。データが正しく結合されない場合は、まず結合キーの設定を確認します。特に、データ型の不一致や形式の違いがないかを詳細に調べます。結合後のデータが期待と異なる場合は、各データソースの更新状況とタイミングを確認します。
パフォーマンスの問題が発生した場合は、まずデータ量と結合条件を見直します。必要に応じて、以下のような最適化を検討します。
1.分析に必要な期間のデータのみを使用する
2.不要なフィールドを除外する
3.適切なキャッシュ設定を行う
4.データの事前集計を実施する
様々なレポートを取り扱っております。用途やシーンに合わせて、最適なレポートを使っていただくことで、日々のレポート作成やデータ分析のお役に立ちます!
レポート一覧はこちら
関連記事
Looker Studio CASE関数の使い方完全ガイド|初心者でも5分でマスター
【サンプル付き】Looker Studio IF関数の使い方|条件分岐で高度な計算フィールド作成
【実例付き】Looker Studio CONCAT・CONTAINS_TEXT関数の使い方|文字列操作完全ガイド
Looker Studio 日付関数と期間設定の完全ガイド|全28関数+実践例で即活用

